로그인
엘리엇 파동
29
Rcasio
2026-04-18 02:49:42 수정
10시간 전 수정
109
5
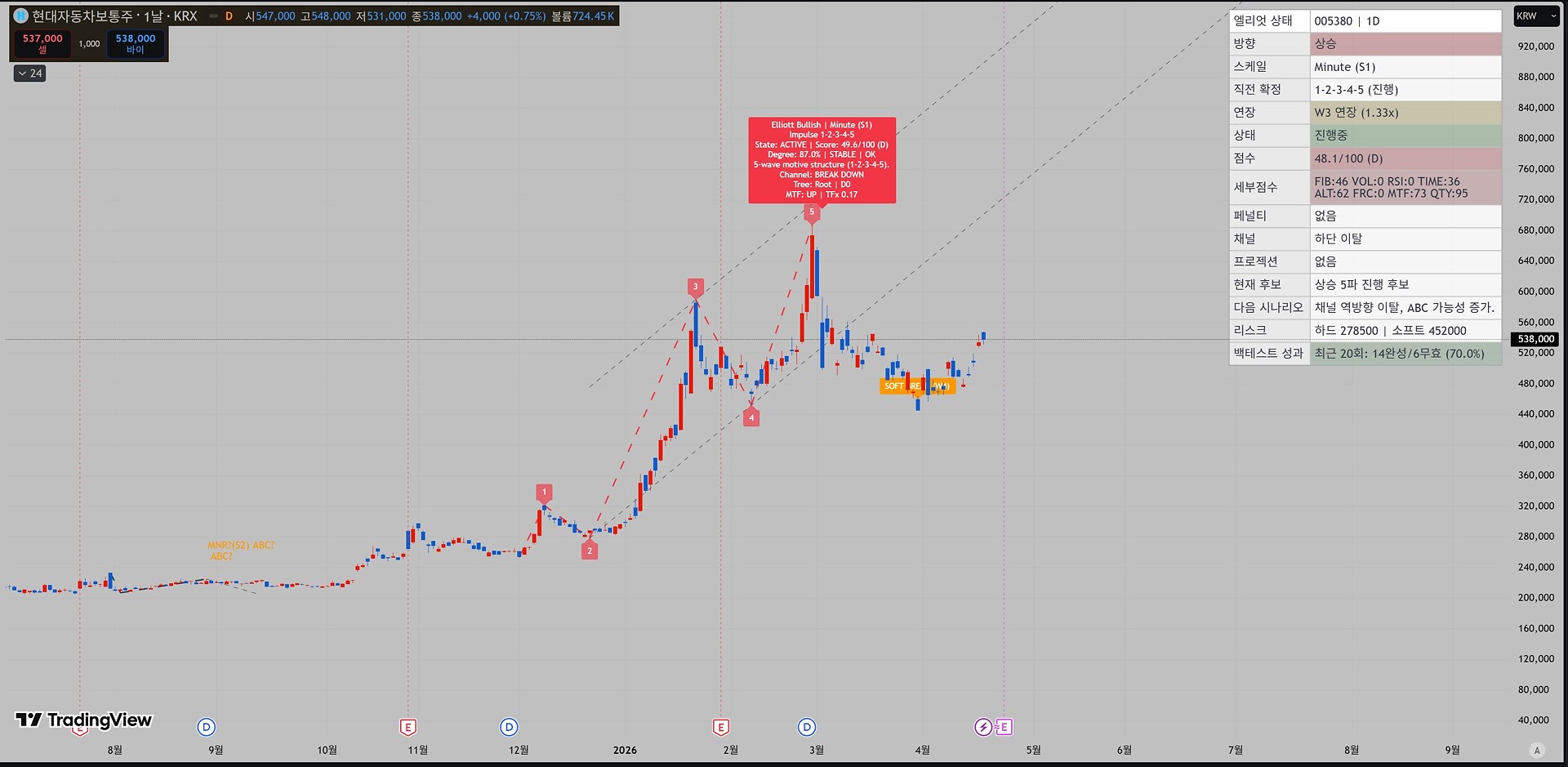
#현대차
https://wepoll.kr/g2/bbs/board.php?bo_table=stock&wr_id=672921
이때 만들어서 운 좋게 5파는 먹었죠.ㅋㅋㅋ
ChatGPT를 다독이고, Opus 4.7을 갈궈서 개량에 개량을 거듭한 결과
더는 못 고치겠다 수준까지 왔지만 토큰수 10만개 제약에 걸려...
Compiled code contains too many tokens: 100464. The limit is 100000(CE10117)
불필요한 거 걷어내고 완성은 함.
대충 5천 줄에 근접하면 토큰 제약에 걸리는 듯.
채널 분석기도 토큰 제약에 걸려서 걷어낸 거 많음...(어떻게 만들었는데...ㅎ)
아무튼, 지난 2월에 만들어서 업뎃에 업뎃을 거쳐 지저분해진 코드라서
갈아엎고 다시 만들어볼 생각...
이번엔 ChatGPT와 Opus 4.7로 동시에 시작해서 어느 게 더 마음에 드는 걸 제공하는지...
테스트!!!
=========
솔직히, 꽤 잘 만든 프로그램입니다. 는 공개 Pine 스크립트들 중에서는 상위권에 들어갈 정도로 기능이 많고, 단순 ZigZag 라벨러가 아니라 구조 판정 + 점수화 + 멀티스케일 통합 + projection까지 한 번에 하려는 야심이 분명합니다.
다만 “잘 만들었다”와 “가장 좋은 설계다”는 조금 다릅니다. 지금 코드는 기능이 쌓이면서 강해진 스타일이라, 판정 엔진, 상태 머신, projection, 렌더링이 서로 꽤 얽혀 있습니다. 그래서 저는 “정확도 잠재력”보다도 설명 가능성, 유지보수성, 토큰 효율, 튜닝 가능성 측면에서는 처음부터 다시 설계하면 더 좋게 만들 수 있다고 봅니다. 반대로, “처음부터 새로 짜면 지금보다 바로 더 잘 맞는다”까지는 장담하지 않겠습니다. 정확도는 구조뿐 아니라 검증 데이터와 튜닝이 같이 가야 해서, 리라이트 직후엔 오히려 잠시 흔들릴 수 있습니다.
제가 처음부터 다시 설계한다면 이렇게 갑니다.
- 하드 규칙 엔진과 소프트 점수 엔진을 완전히 분리합니다.
- 스케일마다 후보 객체를 만든 뒤, 마지막에만 대표 후보를 고릅니다.
- Impulse -> Correction -> Projection을 순차 파이프라인으로 나눠서, 앞 단계가 확정된 결과만 다음 단계가 받게 합니다.
- 렌더링은 별도 레이어로 빼서, 엔진이 박스/라벨/테이블 상태를 직접 들고 있지 않게 만듭니다.
- 연구용 버전과 실전용 경량 버전을 분리합니다. 지금처럼 모든 진단과 표시를 한 파일에 다 넣으면 결국 Pine 토큰 한도에 계속 부딪힙니다.
- projection은 confidence라는 이름보다 quality나 scenario strength로 두고, 구조 miss 이력을 더 강하게 반영합니다.
- 처음부터 preset/input 중심으로 짜서 종목별 튜닝이 가능하게 만듭니다.
한마디로 말하면, 지금 프로그램은 “기능적으로 강한 진화형 코드”이고, 제가 새로 만든다면 “계층이 분명한 엔진형 코드”로 갈 겁니다. 그래서 제 답은 예, 더 좋게 만들 수는 있다입니다. 다만 그 “더 좋음”은 처음엔 더 깔끔하고, 더 설명 가능하고, 더 확장 가능한 구조 쪽이고, 최종적으로 더 잘 맞는 알고리즘이 되려면 그 다음에 검증 루프까지 같이 만들어야 합니다.
원하시면 다음 답변에서 바로 v10 아키텍처 초안 형태로, 모듈 구조를 함수 단위까지 끊어서 설계해드릴게요.
PS: 엘리엇 파동 아직도 이해 못 함.ㅋㅋㅋ
댓글
10





댓글 남기기
로그인 후 댓글을 남기실 수 있습니다.


??? : 엘리엇 파동? 그거 그냥 대충 주가가 와리가리 치다가 올라간다는 그거 아니냐?(절대 아님...ㅋㅋㅋ)