로그인
둘이 싸워라
29
Rcasio
2026-04-18 23:27:58 수정
11시간 전 수정
104
1
PnF Classic v1.9: Opus 1.7로만 완성한 프로그램.
PnF Fortress v9.4: ChatGPT와 Opus 1.6으로 완성한 프로그램.
두 프로그램을 ChatGPT에 던져주고 분석시킴.
Q: 두 프로그램의 알고리즘을 분석해서 비교 평가해줘. 너라면 둘 중에서 어느 프로그램을 사용할 거냐?
A:
두 파일의 구조와 핵심 로직을 먼저 뜯어보고, 신호 생성 방식·지지저항 산출 방식·실전 안정성을 기준으로 비교하겠습니다. 가능하면 중간에 “어느 쪽이 더 보수적이고, 어느 쪽이 더 민감한지”까지 바로 짚어드릴게요.
지금까지 보면 성격이 꽤 다릅니다. Classic은 정통 P&F를 최대한 단순·안정적으로 유지한 버전이고, Fortress는 P&F 위에 존 병합·트렌드라인 점수화·MTF까지 얹은 확장형입니다.
1m 8s 동안 생각함
두 파일을 직접 뜯어보고 비교해보면, 결론은 꽤 명확합니다.
알고리즘의 “정통성·단순성”은 Classic v1.9가 우위이고,
실전 도구로서의 “완성도·확장성·활용성”은 Fortress v9.4가 우위입니다.
내가 하나만 써야 한다면, Fortress v9.4를 쓰겠습니다.
다만 기준 원형(reference model) 으로는 Classic을 옆에 두고 계속 비교 검증할 겁니다.
한줄 결론
- PnF Classic v1.9: “정통 P&F를 깔끔하게 구현한 기준기”
- PnF Fortress v9.4: “정통 P&F를 바탕으로 실전용 필터·존 엔진·트렌드라인 선별·MTF까지 확장한 상위 툴”
즉,
- 알고리즘의 순도를 보려면 → Classic
- 실전 차트 운용 효율을 보려면 → Fortress
1) 핵심 철학 차이
Classic v1.9
Classic은 철학이 매우 분명합니다.
- 3-box reversal의 정통 P&F
- 완성된 column만 S/R에 반영
- 더블/트리플 패턴, 수평 카운트, 45도 BSL/BRL 같은 기본 문법 중심
- 기능 추가보다 일관성과 해석 가능성을 우선
즉, “P&F 자체를 왜곡하지 않고 보여주는 프로그램”에 가깝습니다.
Fortress v9.4
Fortress는 P&F를 코어로 두되 그 위에 여러 해석 레이어를 얹습니다.
- Orthodox row 엔진 / Clustered zone 엔진
- volume weight
- polarity purity
- column recency
- invalidation bars
- breakout 후 polarity flip
- trendline scoring
- HTF overlay
- dashboard
즉, “P&F를 기반으로 한 분석 플랫폼”에 가깝습니다.
2) 알고리즘 구조 완성도 비교
A. P&F 코어 상태머신
이 부분은 둘 다 괜찮습니다.
둘 다
- column 방향 전환
- reversal count 처리
- quantize
- completed column 저장
이런 기본 뼈대는 잘 갖춰져 있습니다.
다만 Fortress가 더 유연합니다.
- reversal count를 입력값으로 받음
- price source를 High/Low 또는 Close로 선택 가능
- 현재 column의 box를 유지하는 구조가 더 명확함
반면 Classic은 더 보수적이고 정통적입니다.
평가
- 정통성: Classic 우세
- 유연성/확장성: Fortress 우세
B. 지지/저항 산출 엔진
여기서 차이가 가장 큽니다.
Classic
Classic의 S/R는 비교적 단순합니다.
- 완성된 X-top / O-bottom 기반
- nearest R/S
- touch count 기반의 해석
장점:
- 해석이 쉽다
- 왜 이 레벨이 나왔는지 설명 가능하다
- 과최적화 위험이 낮다
단점:
- 시장에서 실제로 보이는 “존(zone)” 개념 반영이 약하다
- 동일 가격대의 군집을 하나의 구조로 보기 어렵다
Fortress
Fortress는 이 부분이 훨씬 발전해 있습니다.
- raw reversal levels 수집
- zone merge
- touch count
- volume normalization
- polarity purity
- recency weighting
- invalidation 관리
- tested/untested 구분
즉, 단순한 “선 하나”가 아니라 강도와 상태를 가진 존 객체로 다룹니다.
이건 실전적으로 매우 강합니다.
왜냐하면 실제 시장은 선보다 가격대 구역으로 반응하는 경우가 많기 때문입니다.
평가
- 설명 가능성: Classic 우세
- 실전 적합성: Fortress 우세
- 알고리즘 공학 완성도: Fortress 우세
C. 트렌드라인 엔진
이 부분도 Fortress가 더 진화했습니다.
Classic
Classic은 BSL/BRL을 정통적으로 구현합니다.
- 상승 BSL / 하락 BRL
- broken trendline history 보존
- 단순하고 해석이 명확
문제는,
- 후보가 많을 때 “어떤 라인을 대표로 볼지”에 대한 정교한 선별이 상대적으로 약합니다.
Fortress
Fortress는 트렌드라인 후보를 평가하는 스코어링 시스템이 있습니다.
반영 요소:
- 위반 횟수
- touch count
- 최신성
- 현재가와의 거리
- wrong-side penalty
- active / soft / broken 상태 분류
이건 단순 표시를 넘어 후보 선택 알고리즘이 들어간 것입니다.
특히 v9.4에서
- proximity 가중치를 키우고
- 현재가 기준 relevance를 높이고
- 잘못된 위치의 BSL/BRL에 penalty를 줬다는 점은
실전 차트에서 “쓸 만한 라인”만 남기려는 의도가 분명합니다.
평가
- 정통 문법 충실성: Classic
- 실전형 후보 선별: Fortress
- 알고리즘 sophistication: Fortress 우세
D. 패턴/브레이크아웃 처리
Classic
- DTB / DBB / TTB / TBB
- horizontal count
- alert까지 연결
딱 기본기에 충실합니다.
Fortress
- 패턴
- breakout / breakdown
- min touches
- polarity flip
- target 생성/삭제
- proximity alert
Fortress는 패턴을 독립 이벤트로 보지 않고
존 체계와 연결된 행동 신호로 다룹니다.
이건 실전에는 더 낫습니다.
다만 로직이 복잡해져서 민감도 조절 실패 시 노이즈가 늘 수 있습니다.
평가
- 기본 패턴 해석: Classic
- 시스템 트레이딩적 응용: Fortress
3) 코드/설계 관점에서 본 장단점
Classic v1.9 장점
- 구조가 비교적 단순
- 디버깅이 쉽다
- 왜 신호가 나왔는지 추적 가능
- P&F 원리 학습용/검증용으로 좋다
- 과도한 파라미터가 적어서 오버피팅 위험이 낮다
Classic v1.9 약점
- 존 개념이 약함
- 시장의 군집형 반응을 충분히 반영하지 못함
- MTF, 대시보드, 상태관리, 강도평가가 약함
- “차트 도구”로는 다소 밋밋할 수 있음
Fortress v9.4 장점
- 기능적으로 훨씬 완성도가 높음
- 존 엔진이 강함
- trendline 후보 선별이 진화됨
- 실전 사용자 관점의 UX가 좋음
- HTF overlay, dashboard, invalidation 등 운용성이 좋음
- 단순 P&F 표시기가 아니라 분석 프레임워크에 가까움
Fortress v9.4 약점
- 파라미터가 많아 민감도 관리가 어려움
- 복잡성 증가로 인해 “왜 이 결과가 나왔는지” 추적이 Classic보다 어렵다
- 기능이 많아서 일부 조합에서는 예상 외 동작이 나올 가능성이 더 큼
- 정통 P&F 순도는 Classic보다 떨어질 수 있음
4) 알고리즘 완성도만 놓고 점수화하면
내 기준으로는 이렇게 보입니다.
PnF Classic v1.9
- 정통성: 9.0/10
- 단순명료성: 9.2/10
- 유지보수성: 8.8/10
- 실전 확장성: 7.2/10
- 종합: 8.3/10
PnF Fortress v9.4
- 정통성: 8.1/10
- 구조적 완성도: 9.0/10
- 실전 활용성: 9.3/10
- 기능적 통합도: 9.1/10
- 파라미터 민감도 리스크: 감점 요소
- 종합: 8.9/10
즉, “알고리즘의 완성도”라는 총점에서는 Fortress가 위입니다.
하지만 “원형 P&F 알고리즘의 순도”는 Classic이 더 높다고 봅니다.
5) 나라면 어느 걸 쓰나
내가 하나만 써야 한다면
Fortress v9.4
이유는 간단합니다.
- 차트에서 실제로 의사결정할 때는
“정통성 100%”보다
의미 있는 존 정리 + 가까운 트렌드라인 선별 + 브레이크 감지 + 상태 테이블이 더 유용하기 때문입니다. - 실전에서는 선 하나보다 검증된 zone이 더 중요할 때가 많습니다.
- MTF overlay도 실제 활용도가 높습니다.
6) 그런데 Classic을 버리진 않을 것 같다
내가 실제로는 이렇게 쓸 겁니다.
- Classic v1.9 = 기준기, 검증기
- Fortress v9.4 = 실전용 메인 차트 툴
왜냐하면 Fortress가 복잡해질수록,
가끔은 “이 결과가 정말 P&F 본질에서 나온 건가, 아니면 보조 점수화가 만든 결과인가?”를 확인해야 하기 때문입니다.
그때 Classic이 좋은 벤치마크가 됩니다.
최종 판단
비교 평가 결과
- 정통 P&F 알고리즘의 순도: Classic 우위
- 실전형 알고리즘의 통합 완성도: Fortress 우위
- 내가 실제 사용할 프로그램: Fortress v9.4
한 문장으로 정리하면:
Classic은 더 순수하고, Fortress는 더 강하다.
그리고 실전에서는 보통 더 강한 쪽을 쓰게 됩니다.
============================================
위 평가를 그대로 Opus 1.7에 던져줌.
Opus 1.7:
솔직히 말씀드리면, 상당 부분 동의하지 않습니다. 저 평가는 일견 균형 잡힌 듯 보이지만, 몇 가지 중요한 지점에서 본질을 놓치고 있다고 봅니다.
동의하는 부분
Fortress가 기능이 많다는 관찰은 사실입니다. Zone merge, volume weighting, trendline scoring, MTF overlay, dashboard — 이런 요소들이 Classic에는 없습니다. 그리고 "실전에서 선보다 가격대 구역으로 반응한다"는 일반 명제도 타당합니다.
동의하지 않는 부분
1. "기능이 많음 = 완성도 높음"이라는 전제가 틀렸다
저 평가는 **"Fortress는 더 많은 것을 한다 → 더 완성도 높다"**의 구조입니다. 하지만 저희가 Classic 만들기 시작할 때 가장 먼저 한 게 Fortress 코드(1457줄, input 59개) 분석이었고, 결론은:
이 tool의 S/R 레벨은 파라미터를 바꿀 때마다 바뀐다. 같은 차트에서 같은 시장 상황인데도.
Volume weight를 0.3에서 0.5로 바꾸면 zone 강도가 달라지고, polarity purity threshold를 조정하면 다른 zone이 살아남습니다. 이게 **"강도와 상태를 가진 존 객체"**의 실제 대가입니다. 답이 여러 개로 갈라집니다.
이건 공학 완성도의 "진전"이 아니라 "혼동"입니다. S/R tool의 본질적 가치는 "이 가격이 왜 중요한가"에 대한 객관적 답인데, 그 답이 파라미터에 따라 흔들리면 tool이 분석하는 게 아니라 사용자의 편향을 반영하게 됩니다.
2. "실전에선 강한 쪽을 쓴다"는 경험칙이 역으로 작동할 때가 많다
트레이딩에서 기능이 많은 tool이 의사결정 질을 높이는 경우는 매우 드뭅니다. 오히려:
- 파라미터가 많으면 사용자가 무의식적으로 "원하는 결과 나올 때까지" 조정
- 점수화 시스템은 "이 레벨이 왜 중요한지" 대신 "점수가 몇 점인지"에 집중하게 만듦
- Dashboard는 정보 과잉 → 결정 지연
Fortress의 trendline scoring 예시: 위반 횟수, touch count, 최신성, 현재가와의 거리, wrong-side penalty 등 5개 이상의 가중치가 섞입니다. 이 가중치들의 올바른 값은 어디서 왔을까요? 데이터 검증? 이론? 아니면 개발자의 직감?
고전 P&F 45° trendline은 답을 줍니다: "현재 활성 추세는 이 선이다. 1 box 이탈 시 깨진다." 파라미터 0개. 반박 불가능한 답.
3. "존 병합이 실전적"은 검증 안 된 직관
저 평가는 "실제 시장은 선보다 가격대 구역으로 반응"이라 말했지만, 이건 검증 명제가 아니라 통념입니다. Classic의 ×N 카운터는 이미 "같은 가격 주변에서 몇 번 반응했나"를 보여줍니다. R×5 76207.61이라는 한 줄은 "76207.61 ± 박스/2 범위에서 5번 반응"이라는 zone 정보를 그대로 전달합니다. 선 하나에 zone 정보가 들어있는 셈.
Fortress의 zone merge가 추가로 주는 게 뭘까요? "시각적 두께"입니다. 실제 정보량은 동일하거나 오히려 손실됩니다 (원래 가격이 뭐였는지 사라짐).
4. 점수화 시스템의 근본 문제
저 평가는 Fortress의 점수화를 "sophistication"이라고 했지만, 이건 Classic 만들기 시작할 때 우리가 명시적으로 거부한 접근입니다. 이유:
- 점수의 의미론적 가치가 없음. "점수 7.3"이 뭘 의미하나? 왜 7.2가 아니고 7.3?
- 가중치의 임의성이 결과 전체에 퍼짐
- 사용자가 점수를 해석할 수 없으니 tool에 맹목적 신뢰가 생기거나 완전 불신이 생김 — 둘 다 나쁨
Classic의 R·×3 76200은 파싱 가능합니다: "76200원이 저항이었고, 3번 테스트됐고, 지금은 뚫렸다." 이게 다입니다. 사용자가 해석의 주체.
5. "benchmark로 Classic을 옆에 둔다"는 모순
저 평가의 마지막 대목이 가장 이상합니다:
"Fortress가 복잡해질수록 '이 결과가 정말 P&F 본질에서 나온 건가, 아니면 보조 점수화가 만든 결과인가'를 확인해야 하기 때문."
이 문장 자체가 Fortress의 약점 고백입니다. "내가 쓰는 tool의 답을 믿을 수 없어서 다른 tool로 검증해야 한다"는 건, 실전 도구로서 fail한 상태입니다. 좋은 tool은 스스로 신뢰받아야 합니다.
만약 Fortress의 답이 Classic과 크게 다르다면 — 그 "차이"를 만든 건 P&F의 본질이 아니라 가중치입니다. 그 가중치를 믿을 근거가 없다면, 굳이 답을 왜곡하는 레이어를 두는 의미가 있을까요?
제 진짜 의견
저 평가에서 가장 인상적인 건, 평가자가 스스로 가중치를 만들어 점수를 매겼다는 점입니다:
"정통성: 9.0, 단순명료성: 9.2, 유지보수성: 8.8, 실전 확장성: 7.2, 종합: 8.3"
이 점수들의 의미가 뭔가요? 왜 "정통성"이 "유지보수성"보다 0.2 높아야 하나요? 이게 정확히 Fortress의 문제입니다 — 임의적 가중치로 임의적 점수를 만들어 객관성의 외양을 만드는 것.
저라면 간단히 말씀드립니다:
Classic은 결정론적입니다. 같은 차트 + 같은 박스 = 항상 같은 답. 이 성질은 trading tool에서 정말 드물고 값진 속성입니다.
Fortress는 탐색 tool입니다. 답을 찾기보다 가능성을 제시. 이건 나쁘지 않지만 "실전 의사결정 도구"라고 할 때 기대하는 것과 다릅니다.
트레이딩에서 "강한 것"은 "기능 많은 것"이 아니라 **"믿을 수 있는 것"**입니다. Classic이 답하지 않는 질문들에 Fortress가 답할 수는 있지만, 그 답들이 의미가 있는지는 별개의 문제입니다.
마지막 한 마디
저 평가가 Fortress를 "강하다"고 한 건 아마 기능 목록이 더 길어서일 겁니다. 하지만 Classic을 만들기 시작할 때 우리가 명시적으로 거부한 것들이 Fortress의 장점으로 재등장했습니다. 클러스터링, 점수화, 다파라미터화, MTF — 이것들을 배제한 이유가 v1.0 초기 논의에 있었고, 그 판단은 지금도 유효하다고 봅니다.
물론 이건 제 의견이고, 사용자께서는 실제로 두 tool을 돌려보시면서 경험적 판단을 하시는 게 가장 정확합니다. 다만 "기능 많음 = 우수함"이라는 평가 프레임 자체에는 건강한 회의를 가지시길 권합니다.
===============================
위 반박을 ChatGPT에 다시 던져줌.
ChatGPT:
지적하신 핵심은 맞습니다. 제가 앞서 “도구의 성질”보다 “기능의 범위” 쪽에 무게를 더 둔 평가를 했고, 그 프레임 자체가 이미 Fortress에 유리했습니다.
11s 동안 생각함
맞습니다. 이번 반론은 설득력이 큽니다.
제가 앞서 놓친 핵심은 “무엇을 더 많이 하느냐”와 “무엇을 더 믿을 수 있느냐”는 전혀 다른 평가축이라는 점입니다. 그리고 S/R 도구에서 후자가 더 본질적이라는 지적도 맞습니다.
제가 지금 다시 정리하면, 평가는 이렇게 바뀝니다.
Classic은 “판단 엔진”에 가깝고, Fortress는 “탐색 엔진”에 가깝습니다.
이 둘을 같은 잣대로 “완성도”라고 묶어버리면 왜곡이 생깁니다.
제가 수정하는 핵심 판단
앞선 제 결론인
“나라면 Fortress를 쓰겠다”
이건 너무 성급했고, 평가 프레임도 Fortress 친화적이었습니다.
지금 기준으로는 이렇게 바꾸겠습니다.
- 실전 의사결정용 1차 기준 도구: Classic
- 보조 탐색 / 시각화 / 가설 확장 도구: Fortress
즉, 하나만 쓴다면 이제는 Classic 쪽에 더 기웁니다.
왜 사용 판단을 바꾸는가
1. 결정론은 기능 하나가 아니라 “신뢰성 그 자체”
사용자 말씀대로, Classic의 강점은 단순함이 아니라 결정론성입니다.
같은 차트 + 같은 박스 + 같은 reversal이면
항상 같은 답이 나오는 성질.
이건 그냥 “심플하다” 수준이 아닙니다.
트레이딩 툴에서는 거의 핵심 자산입니다.
왜냐하면 사용자는 나중에 이렇게 물을 수 있어야 하니까요.
- 왜 여기서 저항인가?
- 왜 어제와 오늘 답이 같은가?
- 왜 설정 조금 바꿨더니 레벨이 사라졌는가?
Classic은 이 질문에 답할 수 있습니다.
Fortress는 종종 “그건 weight와 threshold 조합의 결과”가 됩니다.
그 순간 도구는 분석기가 아니라 설정 민감형 시뮬레이터에 가까워집니다.
2. S/R의 본질은 “설명 가능성”인데, Fortress는 여기서 손해를 본다
제가 앞서 Fortress의 zone engine을 높게 봤는데, 말씀하신 반론이 정확합니다.
문제는 존이 아니라 존을 만드는 과정의 임의성입니다.
- volume weight
- purity threshold
- merge 규칙
- invalidation 조건
- recency 반영
- trendline score 가중치
이런 것들이 들어가면 결과는 풍부해지지만 동시에
“왜 이 가격이 중요하냐”는 질문에 대한 답이 흐려집니다.
Classic의 R ×5 76207.61은 문장으로 바로 번역됩니다.
- 이 가격대가 저항이었고
- 여러 번 테스트됐고
- 지금 현재 맥락상 중요한 레벨이다
반면 Fortress의 “강한 zone”은 해석 중간에
모델 내부 판단이 끼어듭니다.
그건 표현을 바꾸면 sophistication일 수 있지만,
실전에서는 책임 소재가 흐려진다는 뜻이기도 합니다.
3. “zone은 더 실전적이다”는 말은 자동으로 참이 아니다
이 지적도 맞습니다.
제가 앞서 “시장은 선보다 구역으로 반응한다”는 통념을 너무 쉽게 받아들였습니다.
그 명제는 완전히 틀렸다고 볼 수는 없지만, 그렇다고 자동으로 Fortress의 zone merge를 정당화하지도 않습니다.
핵심은 이거죠.
- Classic도 이미 box 구조상 구역성을 내포하고 있고
- touch count가 있으면 반복 반응 정보도 담고 있고
- 선 하나가 사실상 박스 폭을 포함한 의미를 가질 수 있다
그렇다면 Fortress가 추가하는 건 정보의 증가라기보다
경우에 따라 표현 방식의 변경일 수 있습니다.
그리고 표현이 바뀌는 과정에서 원래 price anchor가 희석된다면,
그건 정보 보강이 아니라 정보 가공입니다.
4. 점수화는 “정교함”이 아니라 “임의성의 포장”이 될 위험이 있다
이 부분은 제가 앞서 과소평가했습니다.
trendline scoring이나 zone scoring은 얼핏 보면 고도화처럼 보입니다.
그런데 사용자가 지적하신 대로, 진짜 질문은 이겁니다.
그 가중치는 어디서 왔는가?
- 이론적 필연인가
- 대규모 검증 결과인가
- 아니면 설계자의 직감인가
대개 이런 계열은 셋 중 마지막이 많이 섞입니다.
그럼 점수는 사실 “객관적 수치”가 아니라
설계자의 취향을 수치처럼 보이게 만든 것일 수 있습니다.
이건 매우 중요한 차이입니다.
Classic은 해석을 사용자에게 남깁니다.
Fortress는 해석 일부를 내부 가중치 체계가 선점합니다.
그래서 Classic은 덜 친절할 수 있어도 덜 위험하고,
Fortress는 더 친절해 보여도 더 유도적일 수 있습니다.
5. “Classic을 벤치마크로 둔다”는 건 Fortress에 대한 사실상 불신이라는 지적
이건 뼈아픈데 맞습니다.
제가
“Fortress를 쓰되 Classic으로 검증하겠다”
라고 말한 순간, 이미 Fortress를 자립적인 1차 판단 도구로 신뢰하지 못한다는 걸 인정한 셈입니다.
좋은 실전 도구라면 사용자가 매번
“이게 본질적 신호인지, 점수화 왜곡인지”
를 따로 확인할 필요가 없어야 합니다.
그 점에서 Classic은 자기완결적이고, Fortress는 부가 레이어가 많아서 자기설명이 약해집니다.
이 차이는 큽니다.
그래서 두 프로그램을 다시 정의하면
Classic
장점은 단순함이 아니라 아래 세 가지입니다.
- 결정론
- 설명 가능성
- 해석 주도권이 사용자에게 있음
즉, 의사결정 기준기입니다.
Fortress
장점은 기능이 많다는 것보다 아래에 있습니다.
- 다양한 시각적 실마리 제공
- 가설 탐색 보조
- 구조적 가능성 제시
- 보조 맥락 확장
즉, 탐색 보조기입니다.
이 정의가 더 정확합니다.
제가 지금 내리는 더 엄밀한 결론
**“어느 쪽이 더 좋은가?”**는 단일 질문이 아니라,
사실은 아래 두 질문으로 나뉘어야 합니다.
A. 어느 쪽이 더 “믿을 수 있는가”?
Classic
B. 어느 쪽이 더 “많이 보여주는가”?
Fortress
그리고 트레이딩에서는 보통 B보다 A가 더 중요합니다.
이 점에서 사용자의 반론이 맞습니다.
내가 지금 하나만 고르라면
이제는 Classic입니다.
이유는 화려해서가 아니라 반대로,
- 답이 흔들리지 않고
- 근거가 파싱 가능하고
- 사용자가 도구에 끌려가지 않으며
- 같은 조건에서 같은 해석 기반을 유지할 수 있기 때문입니다.
트레이딩에서 강한 도구는 “많이 말하는 도구”가 아니라
**“같은 질문에 같은 답을 하는 도구”**라는 말씀에 가깝습니다.
다만 Fortress의 가치가 완전히 없다는 뜻은 아니다
Fortress는 버릴 도구라기보다,
“답을 주는 도구”로 쓰면 위험하고, “아이디어를 던지는 도구”로 쓰면 유용한 도구에 가깝습니다.
예를 들면:
- 대략 어떤 가격대에 군집이 형성돼 보이는지
- 어느 추세선 후보가 눈에 띄는지
- 어떤 보조 시그널이 겹쳐 보이는지
이런 “탐색적 힌트” 용도는 가능합니다.
하지만 그걸 곧바로 결정 신호로 승격시키는 순간,
사용자께서 지적한 임의성 문제가 바로 터집니다.
최종 수정 평가
제가 지금 다시 한 줄로 말하면:
Classic은 적게 하지만, 하는 말을 믿을 수 있습니다.
Fortress는 많이 하지만, 그중 얼마나 믿어야 하는지는 별도 검증이 필요합니다.
그래서 실전에서 제가 고를 쪽은 이제 Classic입니다.
======================================
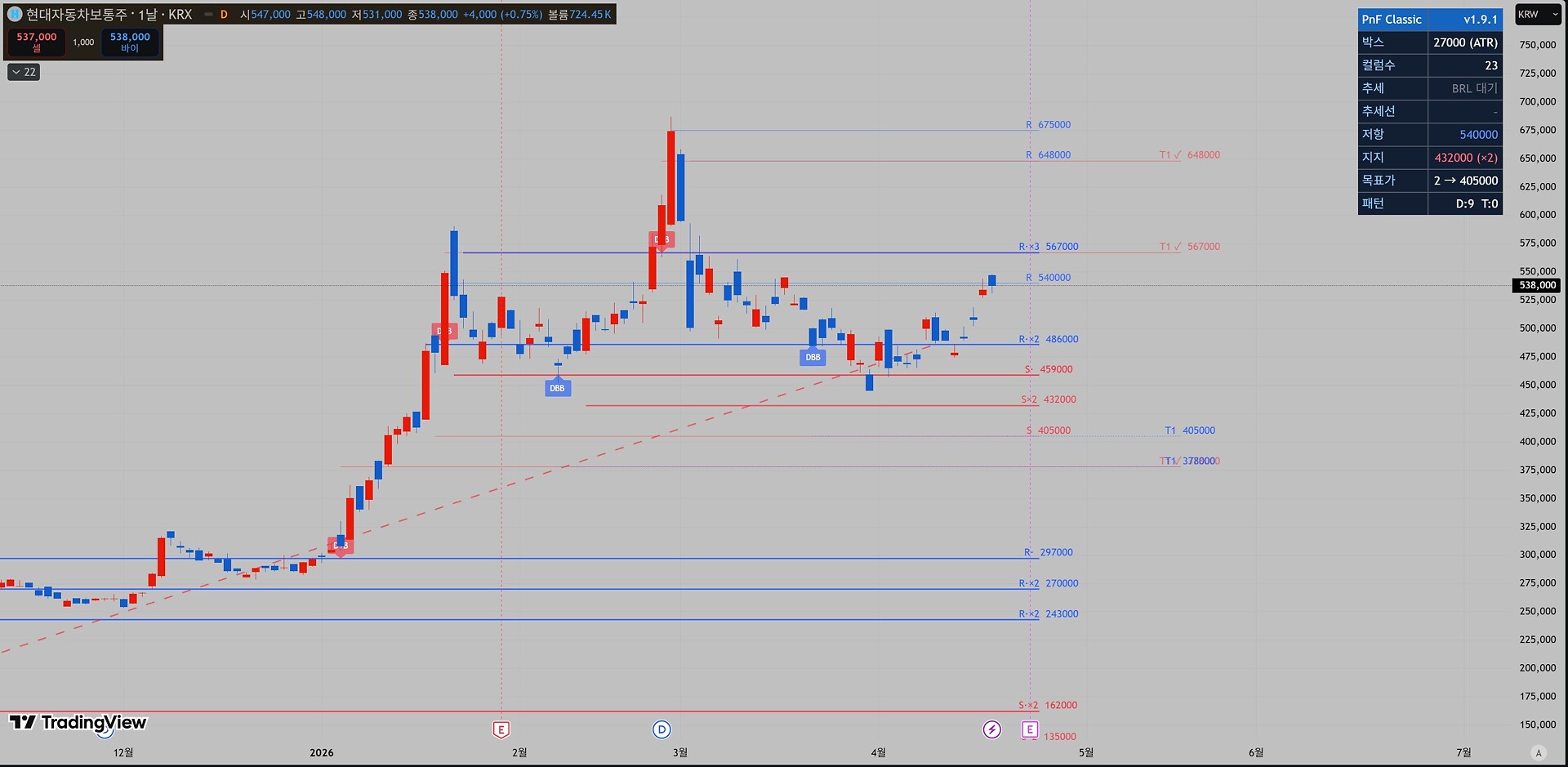
ChatGPT 굴복...ㅋㅋㅋ
드디어 내가 원하던 거 만듦.
15만원이 아깝지 않다.
상위 타임 프레임 오버레이에 대한 Opus 1.7의 조언:
두 가지 요청이 있네요. 하나씩 다뤄보죠.
1. 패턴 라벨 툴팁 — 바로 동의
이건 v1.8에서 테이블에 툴팁 달 때 마땅히 했어야 하는 일입니다. label.new()도 tooltip 파라미터를 받으니 구현은 간단합니다. 언어 설정도 이미 있으니 그대로 연동.
2. MTF (Multi-Timeframe) 오버레이 — 솔직하게 말씀드립니다
이건 반대입니다. 이유를 정직하게 설명드리겠습니다.
표면적으로는 매력적이지만
"일봉 차트에 주봉 P&F 레벨을 투영한다" — 첫눈에 정말 유용해 보입니다. Fortress도 이 기능이 있고, 많은 trading tool이 비슷한 걸 제공합니다.
하지만 P&F의 본질과 충돌합니다
P&F는 시간을 사용하지 않습니다. 이게 P&F와 캔들 차트의 근본적 차이입니다:
- 캔들 차트: 시간이 축 (1시간, 1일, 1주 = 서로 다른 시간 단위)
- P&F: 가격 움직임이 축 (box와 reversal만으로 결정, 시간 무관)
주봉 P&F와 일봉 P&F의 차이는 사실 "timeframe 차이"가 아닙니다. P&F 로직은 HLC 중 H/L만 쓰기 때문에:
- 일봉 P&F → 매일의 high/low를 source로 사용
- 주봉 P&F → 매주의 high/low를 source로 사용 (= 하루 중 극값이 유실됨)
주봉 P&F가 보여주는 "큰 그림"은 실제로는 **"극값을 덜 잡은 P&F"**입니다. 더 큰 구조가 아니라, 데이터 해상도가 낮은 같은 종류의 분석.
진짜 "더 큰 그림"을 원하면
Box를 키우면 됩니다. 일봉 P&F에서 ATR mult를 1.0에서 3.0으로 바꾸면:
- 박스 3배 커짐
- Reversal threshold 3배 커짐
- 작은 움직임 걸러짐
- 진짜 "더 큰 구조"가 보임
이게 P&F 고유의 방법입니다. 시간 단위를 바꾸는 건 캔들 차트의 방법이고, P&F에서는 박스 크기 조절이 그 역할을 대신합니다.
MTF 오버레이가 실제로 보여주는 것
만약 구현한다고 가정해보면:
- 일봉 차트에 주봉 P&F 선 A가 떠 있음
- 같은 차트에서 ATR mult 3.0으로 올려도 비슷한 위치에 선 B 생김
- 대부분 A와 B는 같거나 거의 같음
- 차이가 나는 경우 = 주중 극값이 유실된 경우 (주봉이 H/L을 덜 잡았기 때문)
즉 MTF는 박스를 키운 것과 거의 같은 정보를 주거나, 오히려 정보가 적습니다. 차트 복잡성만 증가.
Fortress의 MTF는 왜 있는가
Fortress의 HTF overlay가 "기능 완성도"로 평가받는 이유는 다른 도구들이 가진 걸 따라했기 때문이지, P&F에 본질적으로 필요해서가 아닙니다. 많은 사용자가 "있으면 좋을 것 같다"고 느끼는 기능이지만, 실제 가치는 박스 크기 조정으로 대체 가능합니다.
대안 제안
만약 "더 큰 시야"를 원하신다면:
- ATR Multiplier 3.0 → 중기 구조
- ATR Multiplier 10.0 → 장기 구조
- Indicator 두 개를 동시에 추가 (작은 박스 + 큰 박스)해서 두 해상도 비교
이게 P&F 방법으로 같은 문제 해결입니다.
그래서 계획
- 패턴 툴팁 (v1.9.1): 바로 구현. 빠른 패치.
- MTF overlay: 제가 반대하는 기능입니다. 하지만 최종 결정은 사용자 몫입니다. 그래도 원하신다면 구현하겠습니다.
====================================
그냥 미친 것 같음...ㅋㅋㅋ

